








 108. (Agosto 2020) Música y entropía - II
108. (Agosto 2020) Música y entropía - II |
 |
 |
 |
| Escrito por Paco Gómez Martín (Universidad Politécnica de Madrid) | ||||||||||||
| Sábado 01 de Agosto de 2020 | ||||||||||||
1. Modelos musicalesEsta es la segunda entrega de la serie Música y entropía. En el primer artículo [Góm20] examinamos de manera general el concepto de entropía y su relación con la música y el análisis musical. Describimos allí el origen moderno de ese interés —el trabajo de Meyer [Mey56]— así como ideas recientes de la aplicación de la entropía al análisis musical. Consideramos tanto el potencial analítico de la entropía como sus limitaciones. En este artículo vamos a examinar la entropía en el contexto más general de los modelos musicales; en particular, vamos a hacer una recensión del artículo Minimum description length modeling of musical structure [Mav08]. Este artículo contiene una profunda reflexión sobre los modelos musicales, la complejidad de estos (aquí es donde entra la entropía), una propuesta de modelo, los modelos de descripción mínima, y una aplicación de estos al canto litúrgico griego. 1.1. ModelosEl artículo de Mavromatis abre con una frase contundente: ”el problema de la selección de los modelos es de suma importancia en todos los estudios empíricos”. La primera pregunta que surge aquí es: ¿qué es un modelo? El concepto de modelo aparece al final de un camino de conceptos previos que empiezan con el concepto mismo de fenómeno. Un fenómeno es cualquier suceso que puede ser observado. Por observable entendemos sucesos que pueden ser percibidos por los sentidos. Los fenómenos se pueden clasificar de muchos modos, pero hay dos grandes categorías: los fenómenos cuantificables y los fenómenos no cuantificables. Los primeros admiten una descripción numérica y los segundos, no. En el caso de la entropía, los modelos musicales van a ser con frecuencia cuantificables, esto es, se van a construir en base a los aspectos cuantificables de la música tales como la frecuencia de las notas, su altura, la duración, los grados de la escala, entre otros. Los modelos cuantificables suelen ser modelos matemáticos y computacionales. Un modelo matemático consta de los siguientes componentes:
Sin embargo, como dijimos arriba, el modelo matemático es parte de un proceso más general llamado modelización matemática. Los bloques constituyentes de una modelización matemática son:
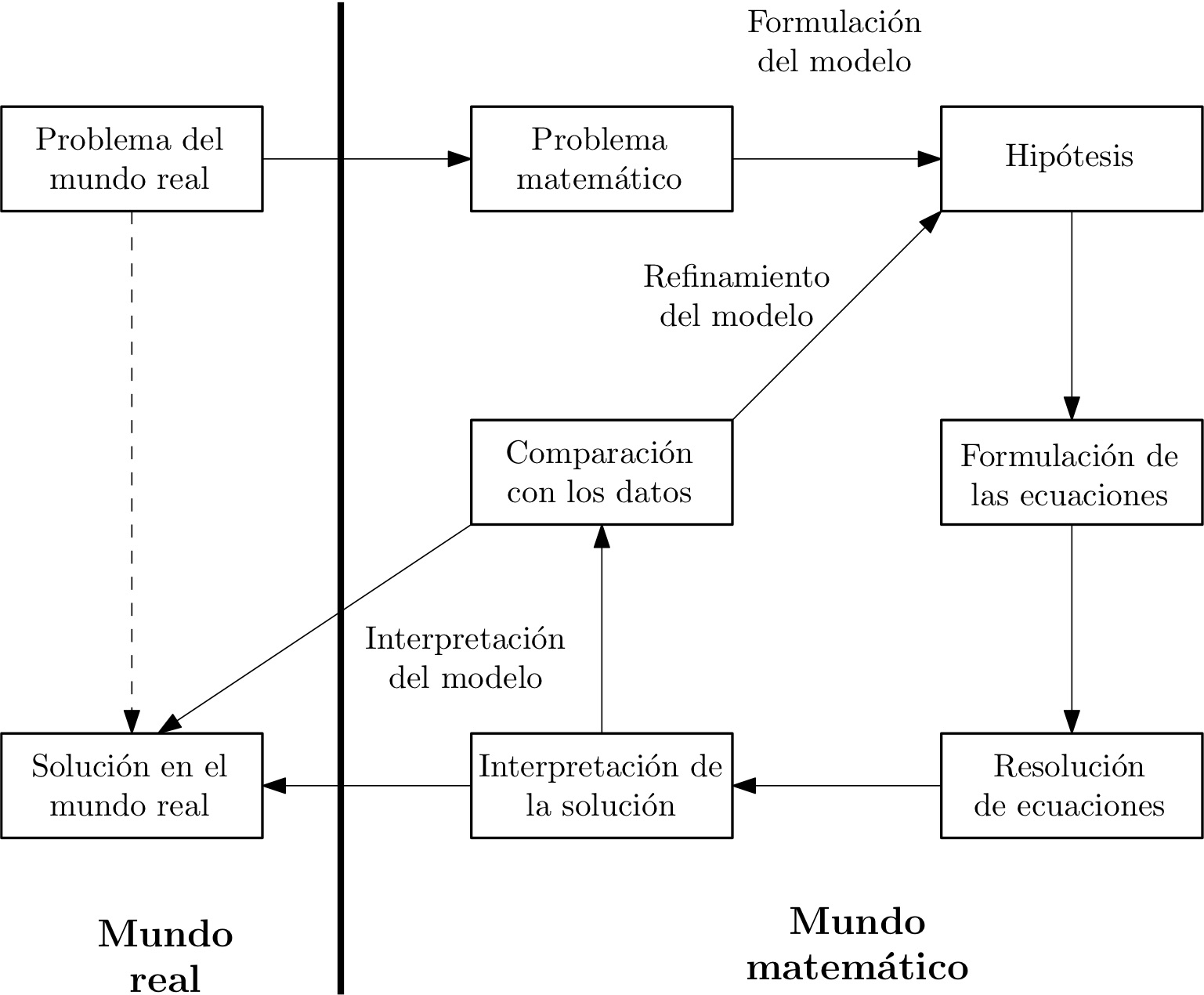
Para más información sobre modelos, consultése el artículo de la Wikipedia Conceptual model [Wik20]. La figura de abajo resume la discusión anterior.
Figura 1: Modelización matemática
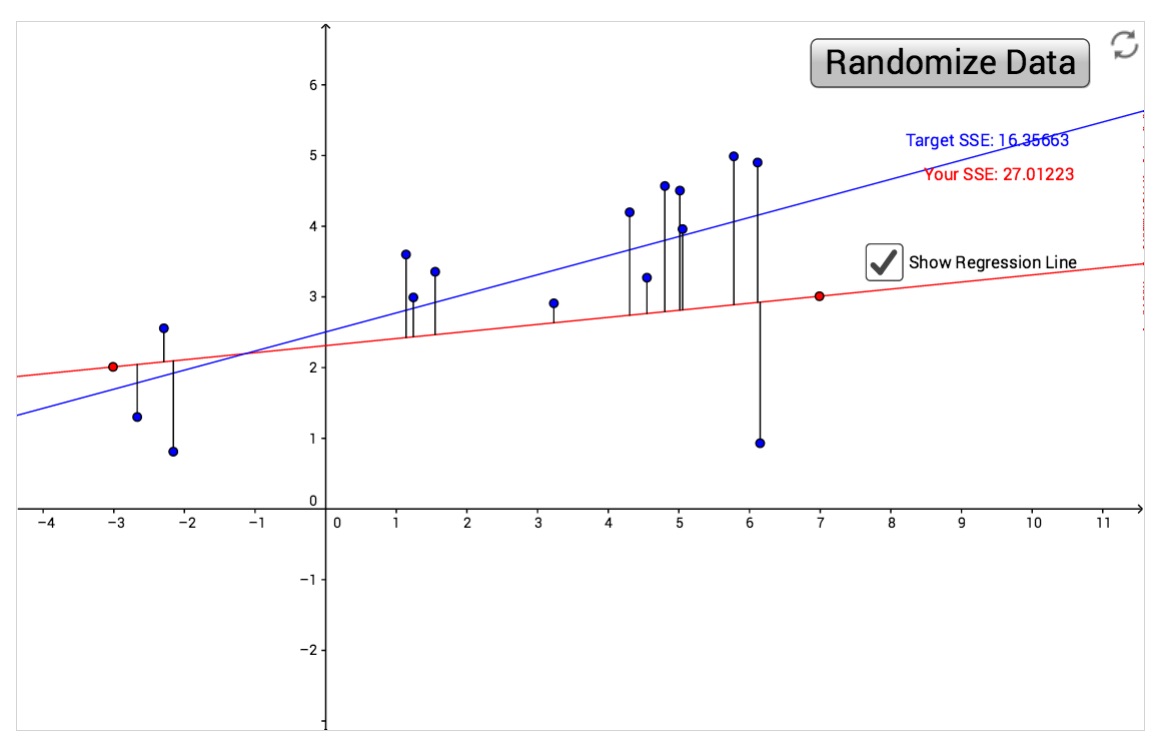
1.2. Evaluación de modelosNormalmente, la calidad o bondad de un modelo se evalúa en función de cuán precisas son sus explicaciones y predicciones hechas a partir de los datos observados. Mavromatis da un paso conceptual hacia delante y propone evaluar la calidad de un modelo en base la capacidad explicativa y predictiva del modelo y además en base a la propia complejidad del modelo (a igual capacidad explicativa y predictiva, son más preferibles los modelos simples a los modelos complejos simplemente por pura aplicación del principio de parsimonia). La manera en que Mavromatis evalúa la complejidad de los modelos tomando prestadas ideas de la teoría de la información. En un modelo musical, la estructura musical está caracterizada por variables simbólicas que representan diversos aspectos de la música tales como la altura de sonido, duración, dinámica, armonía, etc. Un modelo trata de identificar esas variables y su aparición. Esto da lugar a su vez a lo que Mavromatis llama restricciones sintácticas, las cuales dependen del estilo musical. Los valores que toman las variables del modelo se presentan en forma de regularidades estadísticas, las cuales dan lugar a patrones de comportamiento musical. Un campo fecundo de investigación musical es la detección de esos patrones. Volviendo al concepto de parsimonia, perseguiremos que nuestro modelo sea tan simple como sea posible y al mismo tiempo tenga una buena capacidad explicativa y predictiva. Un buen ajuste entre un modelo y los datos se llama bondad del ajuste. En la figura de abajo tenemos un ejemplo sencillo. Supongamos que en nuestro fenómeno observamos una variable dependiente y, representada en el eje Oy, como función de una variable independiente x, representada en el eje Ox. Los puntos negros son las observaciones; se trata de pares de puntos (x1,y1),…,(xn,yn), suponiendo n observaciones. La siguiente pregunta es qué tipo de relación hay entre las variables x e y (en nuestro ejemplo ambas son numéricas). Un modelo muy simple es el modelo lineal, que supone que hay una relación lineal del tipo y = ax + b (una recta), donde a,b son parámetros a determinar en función de los datos observados. La recta de color azul es la recta que mejor explica los datos, mientras que la recta roja arroja un peor modelo. La bondad del modelo es un valor que en la figura aparece como SSE; el mejor modelo es el que tiene este valor lo más bajo posible. Este valor mide los errores cometidos por el modelo al aproximar los datos y en la figura está dado por las distancias verticales de los puntos a la recta. La figura 3 muestra las tres situaciones.
Figura 2: Bondad del ajuste en modelos
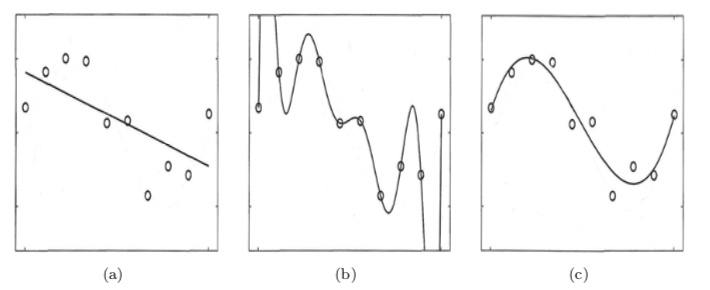
Es posible construir modelos que se ajusten muy muy bien a los datos demasiado bien, reflejando idiosincrasias insignificantes, a base de añadir variables extra. Esto se llama sobreajuste. Esto ocurre cuando el modelo no acierta con el nivel adecuado de abstracción. Produce modelos excesivamente complejos. Lo contrario se llama subajuste: el modelo es pobre y se pierde características importantes del fenómeno. En la figura 3 (a) tenemos un caso de subajuste. El conjunto de datos, que claramente sugiere una forma curva, es aproximado por una recta. En la figura 3 (b) vemos una curva que pasa por todos los puntos observado y el ajuste es perfecto (comete error cero), pero este modelo requiere un alto número de variables independientes que no son parte esencial del modelo. Por último, la figura 3 (c) muestra un modelo más razonable, con pocas variables independientes y con un error de ajuste razonable.
Figura 3: Subajuste y sobreajuste (figura tomada de [Mav08])
2. Modelos de longitud de descripción mínimaEl modelo propuesto por Mavromatis en su trabajo es un modelo de longitud de descripción mínima (LDM, de aquí en adelante). Este modelo es de tipo inductivo, esto es, se construye a partir de la observación de datos asociados al fenómeno bajo estudio. El modelo LDM no solo evalúa el ajuste de los datos, como los modelos clásicos, sino también evalúa la propia complejidad del modelo. Cualquier regularidad detectada en los datos se puede usar para comprimir ese conjunto de datos. Comprimir aquí significa codificar los datos observados de una manera más corta que si los datos se dejan sin comprimir. Cuantas más regularidades se observen en los datos, más se podrán comprimir estos. Por ejemplo, si los datos se pueden codificar a partir de símbolos del alfabeto A = {a,b,c,d}, la cadena C1 = aaaa se puede comprimir como a4, pero la cadena C2 = aabb se puede comprimir como a2b2, cuya compresión es más larga que a4. En este caso, la codificación de C1 tiene longitud 2 (dos símbolos para a2) y la de C2 tiene 4. El LDM mide la bondad de un modelo por la capacidad de comprimir los datos en base a sus regularidades y por la capacidad de comprimirse a sí mismo. Un modelo LDM está constituido por varias piezas. Primero, hay un conjunto de datos D, típicamente obtenidos de la observación del fenómeno. En nuestro caso, consistirán en piezas musicales extraídas de algún corpus musical. A continuación, un modelo M que modeliza el fenómeno, en particular, los datos D. Después, una función de una codificación C, que transforma los datos en un cadena de caracteres tomados de un alfabeto (puede ser un conjunto de números, los bits 1 y 0, caracteres alfanuméricos, etc.). A continuación, una función LC que mide la longitud del código C. Por último, una función de descripción, que está dada por
donde C1,C2 son esquemas de codificación, el primero del modelo M y el segundo de los datos. La expresión D∣M significa la codificación de D según el modelo M. Las codificaciones tienen que tener la propiedad de ser únicas, esto es, dos datos distintos no pueden codificarse por la misma cadena. Esto asegura que se recupera correctamente la información cuando se pasa del código a los datos. En particular, para que esta propiedad se cumpla se requiere que ninguna codificación produzca una cadena que sea prefijo de otra; para más cuestiones técnicas de este tipo recomendamos al lector que consulte el apéndice del artículo de Mavromatis [Mav08]. En general, las mejores codificaciones asignan los códigos más cortos a los símbolos más probables o frecuentes. Esto introduce la idea de probabilidad en el modelo, ya que se hace el recuento de las cadenas más frecuentes en la codificación. Se sabe que siempre hay una codificación óptima que minimiza la esperanza de la longitud de la descripción dada por la distribución de probabilidad P(D∣M). Se llama código de Shannon-Fao. Su función de longitud es
En este punto interviene el teorema de Shannon, que establece que la esperanza mínima de la longitud de la codificación para la salida de un modelo probabilístico M con distribución P(x∣M) está dado por
donde X es el conjunto de símbolos de la codificación. La cantidad HM recibe el nombre de entropía. La idea de Mavromatis es encontrar una función de codificación que se aproxime lo más posible a la cota impuesta por el teorema de Shannon. La función de codificación de Mavromatis se define como sigue. Sea una distribución de probabilidad pi sobre el conjunto de k símbolos y d un parámetro de truncamiento.
donde L*(d) está definida por
La L*(d) solo se suma sobre los términos positivos y por tanto la suma anterior es finita. 3. Modelos de MarkovA continuación hacemos una revisión breve de las cadenas de Markov, que es un tipo de modelos probabilísticos. Este tipo de modelos son muy comunes en música, como ya hemos glosado en otras entregas de esta columna. Mavromatis los usa en conjunción con su modelo LDM. Una cadena de Markov es un modelo de un fenómeno que tiene los siguientes componentes:
La matriz de transiciones es
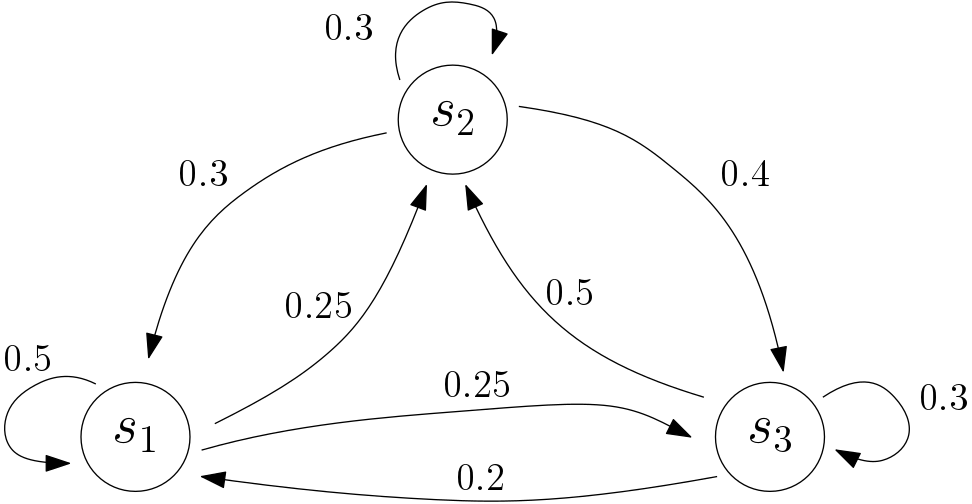
Por ser los números pij probabilidades, las filas de esta matriz siempre suman 1. En la figura de abajo se ve un esquema que refleja la estructura de una cadena de Markov. Este tipo de diagramas, llamados diagramas de estado, son comunes para describir cadenas de Markov.
Figura 4: Una cadena de Markov de tres estados
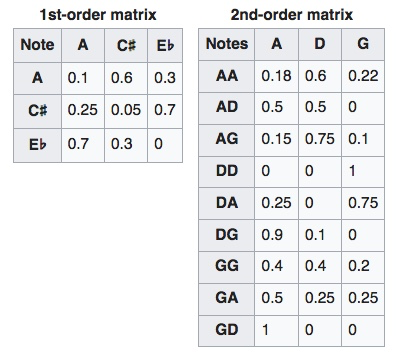
La condición de falta de memoria aparece de manera más general en modelos más abstractos. Se puede pedir que la probabilidad de ir a un estado a otro dependa de un cierto número de estados previos. Por ejemplo, en la figura de abajo a la izquierda se tienen las probabilidades de un conjunto de tres notas entre sí (la, do# y mi♭). En este caso, hablamos de matrices de primer orden. A la derecha de la figura aparecen las probabilidades de continuación de las secuencias de dos notas para otro conjunto de notas diferente (la, do , sol). Ahora la matriz es de orden dos (depende de dos estados previos).
Figura 5: Cadenas de Markov aplicadas al análisis musical
4. Modelos de Markov de longitud de descripción mínimaMavromatis aplica los modelos de Markov de longitud de descripción mínima al canto litúrgico griego. Se trata de una música en que letra y melodía se asocian por medio de reglas estilística tanto musicales como prosódicas. En un trabajo anterior [Mav05] Mavromatis demostró la importancia estructural de ciertas fórmulas arquetípicas melódicas o arquetipos melódicos en este tipo de canto litúrgico. Dichas fórmulas son patrones melódicos de entre 6 a 9 notas y que se pueden acomodar a diferentes patrones prosódicos, incluyendo la longitud y los patrones de acentuación de las palabras. En la siguiente figura se muestran esos arquetipos melódicos; en este caso son todas fórmulas cadenciales.
Figura 6: Fórmulas arquetípicas de la melodía en el canto litúrgico griego (figura tomada de [Mav08])
En la figura se ha usado la siguiente convención: dos x significa sílaba acentuada y una x sílaba no acentuada. Asociado a este estilo musical tenemos unas cuantas reglas que rigen la formación y la sintaxis de los arquetipos melódicos (las reglas sintácticas de las que hablábamos arriba):
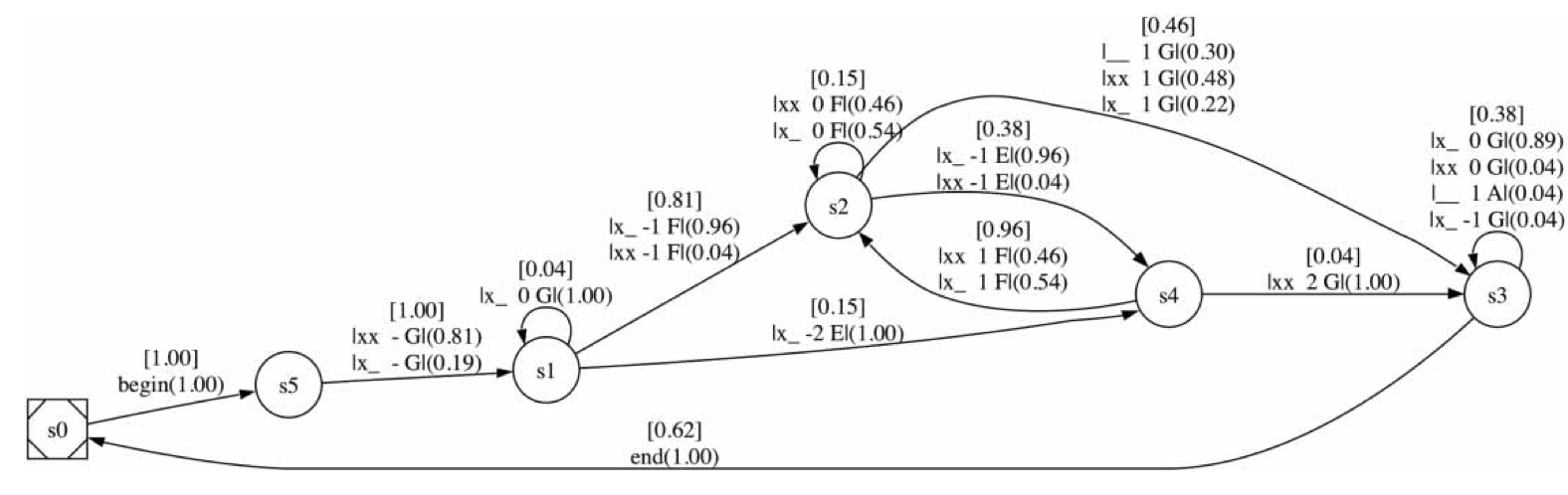
El siguiente paso que da Mavromatis es construir la cadena de Markov. Empieza con un único estado s0 y calcula el total de LDM según las fórmulas que vimos antes. A partir de aquí empieza un proceso en que va añadiendo más estados; llega a hacer hasta 14 estados. En cada paso, calcula las probabilidades a partir de las frecuencias que encuentra en el corpus. En la figura siguiente se ve la cadena de Markov para 6 nodos; en la figura xx significa sílaba acentuada y x_ sílaba no acentuada.
Figura 7: El modelo MDL
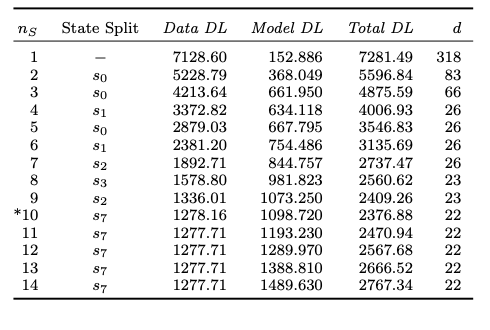
En la tabla de abajo se ven los valores de LDM para los datos y el modelo así como el total de la LDM; nS se refiere al número de nodos de la cadena de Markov. El mínimo de la LDM total se alcanza con 10 nodos (marcado con un asterisco en la tabla).
Figura 8: El modelo MDL
De la ejecución del modelo sobre el corpus de canto litúrgico griego, Mavromatis obtiene las siguientes conclusiones:
Dado que la LDM mínima se alcanza en 10 nodos, se elige este modelo como el óptimo. Usar más nodos daría lugar a sobreajuste y usar menos nodos a subajuste.
Bibliografía[Góm20] P. Gómez. Música y Entropía - I, julio de 2020. [Mav05] Panayotis Mavromatis. A hidden Markov model of melody production in Greek church cant. Computing in Musicology, 14:93–112, 2005. [Mav08] Panayotis Mavromatis. Minimum Description Length Modeling of Musical Structure. Journal of Mathematics and Music, 0:1–21, enero 2008. [Mey56] Leonard Meyer. Emotion and Meaning in Music. University of Chicago Press, Chicago, 1956. [Wik20] Wikipedia. Conceptual model, consultada en 2020. |
||||||||||||


![]()
| © Real Sociedad Matemática Española. Aviso legal. Desarrollo web |